

Abstract / 抽象
我讲个笑话,大伙别笑
我这个python虚拟机比原版python慢100倍
跑下面这段递归代码
def fibonacci_recursive(n):
if n <= 1:
return n
return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
for i in range(10):
print(fibonacci_recursive(i))原版python跑完用了4万纳秒
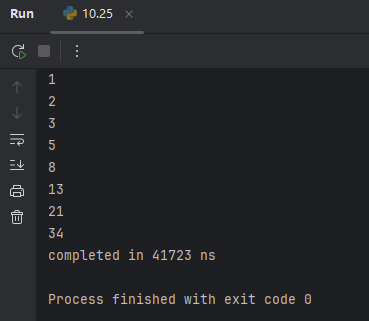
我自己写的这个跑完用了320万纳秒
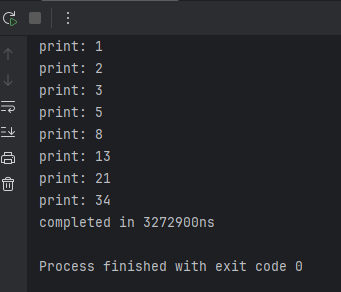
哈哈,您猜怎么着?我不认识您,您自己去回收站呆着吧
其实这个事情是这样的,有次我在部署自己的扫描平台,上传斗象原版npoc的docker镜像,这个npoc镜像大小大概1GB左右,当时网络不是很好,很慢,而且还传失败了,让人非常头痛
于是我在想,npoc这里面poc的逻辑也不复杂,数量也不是非常多,虽然可能镜像里面还有pip和各种依赖包占了不少空间,但是我还是觉得这么大的体积,实在是有点虚胖
我在想是不是用go或者rust去解析npoc的py代码,然后用go或者rust去做python虚拟机用来跑poc;这样体积能小不少
但是用go或者rust去做python虚拟机的工作量也不小,不如我写一个通用的动态库,到时候直接LoadLibrary / dlopen去加载调用,这样代码就能复用了,有什么bug也能统一修复,甚至后期还能做一个加载py代码文件的web容器,像nginx+php那样去处理web请求
目前我考虑用这个python虚拟机做三件事,第一件事就是先做一个burpsuite的流量篡改重放插件,主要用于测试未授权访问这类漏洞;第二件事就是做刚刚第一件事,但是再加一个流量编解码功能,配合cyberchef做;第三件事就是做npoc执行引擎,估计最终能将npoc镜像体积缩小85%以上
我估计大伙可能也不想知道我是怎么实现的,因为性能太垃圾了,但是越是垃圾,我越是要说,因为我不能独自一人承受这个失败
也不是完全失败,起码目前它的体积很小

release编译出来大约3.5m,非常满足缩减体积的需求
从用户的视角开始
如果我是用户,我要怎么使用这个库?
这是我设计交互模式的初心,因为这个python虚拟机不是给用户用的,是给我用的,但是不能因为我不给大伙用,就把交互设计得一团狗屎,因为我自己是这个库的长期用户,一个人不能逼自己吃屎,也不能一直逼自己吃屎
交互最重要的是交互,如何让python调用外部函数?如何优雅的把外部变量放到python里面?这是交互最重要的交互;但是一个人毕竟是一个人,不能把所有人的事情都干了,所以我就用一个人能干完的设计去设计这件事干了
这里我们借鉴js,在js里面万物皆对象,我们也这么搞,弄一个unordered_map作为符号表,任何带名字的东西都往里面塞,每个对象也都带一个符号表,用来存储属性
然后开放操作接口给用户,用户可以直接操作符号表,比如创建对象、注册函数等
怎么注册函数?
创建对象大家好理解,就是创建一个对象,然后设置他的属性,让python代码可以直接读取
但是函数怎么注册?
python有python的字节码,java有java的字节码,如果我在java里面给python注册函数,python要怎么跑?
俺寻思可以用中断的方式去处理
比如说下面这段代码,python调用java的fastjson
import JSON
import hashUtils
text = '{"username":"admin","password":"123456"}'
data = JSON.parse(text)
data['password'] = hashUtils.md5(data['password'])java调用engine.run()执行这段代码,python虚拟机执行到JSON.parse的时候,从JSON里面取出parse函数对象,发现这个函数对象被标记为外部函数,就把当前的上下文丢在那里不管,然后engine.run()函数返回,跟java响应一个函数调用事件,java把JSON.parse执行完之后通过库ABI接口构造返回对象,把属性填好,塞到约定的寄存器里,然后就交给赋值运算符的处理逻辑,继续运行python代码
支持(被)并发
现代编程语言必须支持并发,python也要支持,但是这个支持可以是多种多样的。
像目前这个使用场景,把python作为脚本组件,那这里的并发支持可以是简单的“不使用静态变量”:只需要每个线程创建独立的engine,就可以隔离不同的执行环境,单纯支持多线程调用不同实例就行
编译器实现
说到编译器实现,大伙应该知道有个项目叫cpython,cpython可以直接解析python代码并执行python字节码;既然python官方提供了cpython源代码,为什么我不直接用呢?
其实前期评估这个项目的时候也大概看过cpython,主要是觉得如果要改cpython,首先要把整个cpython项目看一遍,然后要理解整个cpython设计,要在解释器层面上钩子,甚至可能要动字节码;这就感觉有点难度了,因为cpython项目本身很大,网上相关资料也比较少,属于是硬仗
现有的语义分析工具已经可以把python代码直接解析成AST抽象语法树,如果我自己实现编译器和解释器,似乎成本还低一点,因为我可以不完整实现python语法特性,只要跑起来像那么回事就行
编译器、解释器的设计参考了x86汇编,为什么不参考x64的呢?因为几年前搞二进制的时候没坚持下来,x86比较熟,x64没那么熟;当然我也不后悔自己转渗透了,因为就我毕业的时候那个就业环境,搞二进制说不定还要先送两三个月外卖才找得到工作;不过也难说,如果我坚持下来,可能现在这个python虚拟机的性能就不会跟原版差100倍了
言归正传,接下来这里不会介绍所有的语法实现,主要介绍最前面提到的“比原生python慢100倍”的跑分例子
函数定义实现
之前提到过,我把python按照js的思路搞成了万物皆对象。在C++里面,我可以随意使用任何高级实现,比如我可以用字节码DECLARE_FUNC定义一个函数对象,然后把参数列表填进去
DECLARE_FUNC fibonacci_recursive
FUNC_ARG n
JMP xxx
CMP n, 1
JLE xxx
RET n
SUB n, 1
PUSH EAX
PUSH 1
CALL fibonacci_recursive
...上面就是一段定义函数的伪字节码,执行完DECLARE_FUNC时,符号表里面就出现了fibonacci_recursive对象,执行完FUNC_ARG,函数对象的“参数表”属性里面就出现了n;“函数地址”属性则记录从CMP指令开始的函数体的地址;而CMP指令上方的JMP指令,则是避免声明完函数之后就立即执行,正常情况下应该是等到用户调用了再开始执行
这里有一个小约定,就是编译器在从AST生成字节码的过程中,遇到任何表达式/函数调用等产生结果的节点,都默认执行结果存储在EAX,这样编译器设计起来方便一点
当用户调用函数的时候,先根据用户的代码,比如:
a = 1
fibonacci_recursive(a)先根据用户的代码去取参数值,这里的a变量是基础类型,解释器取值的时候会自动进行内存拷贝;取到值之后,将返回地址、参数和参数数量压栈,大伙可能知道,x86里面是没有参数数量压栈这个操作的,但是因为python支持参数默认值嘛,然后我又在用高级语言的思路写解释器,压个参数数量的话,我代码实现起来方便一点;下面就是上面这两行代码的字节码实现
ASSIGN a, 1
MOVE EAX, a
// 下面是函数调用流程
PUSH EIP
PUSH EAX
PUSH 1
CALL fibonacci_recursive大伙可能又知道,在x86里面,返回地址是在参数之后压栈的,但是我自己写解释器嘛,怎么方便怎么来
那么这里就是函数调用的设计了,函数在执行完之后遇上有编译器自动加上的RET指令,无论用户是否写了return都保证函数正常返回
到这里大伙可能会有疑问了,那外部函数怎么办呢?像你之前例子里的JSON.parse,这个函数可没有函数体可以CALL
其实也简单,CALL的时候由解释器直接把EIP寄存器的值挪到CALL后面,然后直接把栈里的EIP弹掉就好了,虽然有点hack的感觉,但也不是不能用
最后还有一个要注意的特性,就是函数内部变量作用域问题,在不使用global关键字的情况下,函数内部对全局变量是只读的,赋值不会生效(改属性会生效)
这个特性可以通过在解释器添加函数作用域解决,搞个栈,函数调用的时候就push函数对象的指针进去,函数返回就pop;并劫持函数内部的所有的"取变量"、"存变量"调用,把作用域限定到函数对象上,这样就把局部变量跟函数对象绑定了,可以实现跟原版python类似的特性:取变量的时候先从函数对象上取,取不到再从符号表中取;存变量的时候只允许存到函数对象上,不允许直接存储到符号表
global关键字就别理他了,懒得做
if子句/return实现
其实很简单,if子句就是不管条件是上面,直接丢进大switch递归,反正最后表达式执行结果在EAX;下面是if子句的编译器代码
void Engine::ifStmt(TSNode node, char *code) {
TSNode condition = ts_node_child_by_field_name(node, "condition", 9);
TSNode block = ts_node_child_by_field_name(node, "consequence", 11);
// 编译if条件,根据约定,运行时if条件的执行结果存储在EAX
this->travel(condition, code);
// jump第一个参数是地址,第二个参数是跳转条件,如果if条件为False则跳转,避免执行if的内容
// 目前不知道if代码块的末尾在哪里,地址先填0占位
auto jmp = new Jump(BCArg(0), BCArg(EAX));
int jmpPos = this->byteCodeSegments.size();
this->submitByteCode(jmp);
// 编译if条件的内容,当if条件为True时执行
this->travel(block, code);
// 得到if结束的地址,patch回去
delete jmp;
jmp = new Jump(BCArg(this->addressCompileTime), BCArg(EAX));
this->byteCodeSegments[jmpPos] = jmp;
}上面代码的this->travel就是我们说的大switch,里面会根据语义块的类型进行逐层的字节码生成,其他解释都写在代码注释里了,大伙自助
return很简单,就把栈里的EIP给POP出来,然后设置EIP寄存器的值,这里假定函数结束的时候能保持栈平衡,因此在调用return的时候从栈里POP出来的东西必须是EIP值;如果不能保持栈平衡,就是编译器bug,总之设计时必须保证栈平衡
for实现
大伙可以注意到我把for单独搞出来写,因为它比较复杂,我哼哧哼哧搞了半个星期都在干这个for循环
在python里面,for循环的一种写法是for i in range(10):,在这句代码里面,range(10)会返回一个迭代器,for会一直跑到迭代器燃尽为止,然而range(10)只会调用一次
这里的难点除了保证跳来跳去地址不歪,还要实现break,还有匿名迭代器的保存等复杂的问题,反正最后解决了,大伙看我注释吧
// break地址压栈 (call流程)压栈参数数量 压栈range参数 调用range返回迭代器 迭代器eax压栈 (call流程)push参数数量0到栈 调用eax迭代器获取i值 备份eax到ecx 检查eax是不是null 条件跳转到'break地址'
// 把ecx设置到符号表 [循环内容] pop,迭代器地址到EAX jmp到'迭代器eax压栈' [break地址],这里把栈里的break地址pop掉,保持栈平衡 [for代码块之后]
void Engine::forStmt(TSNode node, char *code) {
TSNode left = ts_node_child_by_field_name(node, "left", 4);
TSNode right = ts_node_child_by_field_name(node, "right", 5);
TSNode body = ts_node_child_by_field_name(node, "body", 4);
char *leftName = getCodeStr(code, left);
// break地址压栈
int pushBreakPos = this->byteCodeSegments.size();
this->submitByteCode(new Move(BCArg(EAX), BCArg(0)));
this->submitByteCode(new Push(BCArg(EAX), BCArg()));
// call流程
this->travel(right, code);
int pushIterAddress = this->addressCompileTime;
this->submitByteCode(new Push(BCArg(EAX), BCArg()));
this->submitByteCode(new Push(BCArg(), BCArg(0)));
this->submitByteCode(new Call(BCArg(EAX), BCArg()));
this->submitByteCode(new Move(BCArg(ECX), BCArg(EAX)));
this->submitByteCode(new IsNull(BCArg(EAX), BCArg()));
// 条件跳转到'break地址'
int moveBreakPos = this->byteCodeSegments.size();
this->submitByteCode(new Move(BCArg(EBX), BCArg(0)));
this->submitByteCode(new Jump(BCArg(EBX), BCArg(EAX)));
// 把ecx设置到符号表
this->submitByteCode(new Move(BCArg(std::string(leftName)), BCArg(ECX)));
this->travel(body, code);
// 恢复函数地址到EAX
this->submitByteCode(new Pop(BCArg(EAX), BCArg()));
this->submitByteCode(new Jump(BCArg(pushIterAddress), BCArg()));
int breakAddress = this->addressCompileTime;
delete this->byteCodeSegments[pushBreakPos];
this->byteCodeSegments[pushBreakPos] = new Move(BCArg(EAX), BCArg(breakAddress));
delete this->byteCodeSegments[moveBreakPos];
this->byteCodeSegments[moveBreakPos] = new Move(BCArg(EBX), BCArg(breakAddress));
this->submitByteCode(new Pop(BCArg(EAX), BCArg()));
delete[] leftName;
}咱也别管上面的细节是不是跟原版python一致,反正风味差不多就行
性能焦虑
虽然我口口声声性能不重要,但是我很担心万一哪天性能真的成为问题,而我无法解决
目前我还没做具体的性能分析,但是我大概能猜到解释器性能低下的原因
最大的原因应该是内存分配问题,我实现的解释器是通过解析字节码的id,然后new对应的字节码对象出来,再调用对应的函数执行。这一段充满了大量的内存分配和内存拷贝,我知道这个实现很屎,但是我已经在这个python项目上花太多时间了,我必须抽身出来学习研究攻防渗透,过段时间自我感动了之后再回来玩python
本文最早提到的跑分其实是优化过性能的,底层编译了微软的mimalloc,mimalloc覆盖了c/c++原版的malloc/free/new/delete,性能会好一点,实测提升大概在25%,本来跑那串代码要400万纳秒的,优化完变成300万纳秒左右
后期优化也可以着重编译优化,比如常量合并、缩减字节码的“啰嗦程度”、加强单个字节码功能、减少运行时判断等
Comments | NOTHING