

经常使用记忆力的大伙可能会记得,我之前写过一个基于语义分析的API分析工具,如果大伙不记得也没关系,因为我记得
这个工具是年前为了保证某个项目能完成得更全面、更有深度、更强劲、更持久、更有使命、更有价值、更能卖货,从而一时兴起研发出来的;然而过了年之后,我发现这个工具完全就是照着那个项目的任务目标建的,有种照着题出答案的感觉,拿到别的项目去实战就寂静无声了
为了这个项目超越我目前最有价值的产品:报告生成器的炫彩RGB保存按钮,我煞费苦心,但是先让大伙看看我的炫彩RGB保存按钮:

这个炫彩RGB按钮在编辑页面的开头和结尾各一个,关于不采用其他《防忘记保存方案》的原因我在下次报告生成器更新的时候再说
刚才说到为了使API FUZZ工具不沦为路边一条,我研究了之前广泛使用的前端打包器webpack的特点,发现webpack打出来的东西,如果js文件是按需加载的,一般会生成很多chunk文件
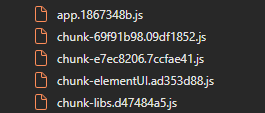
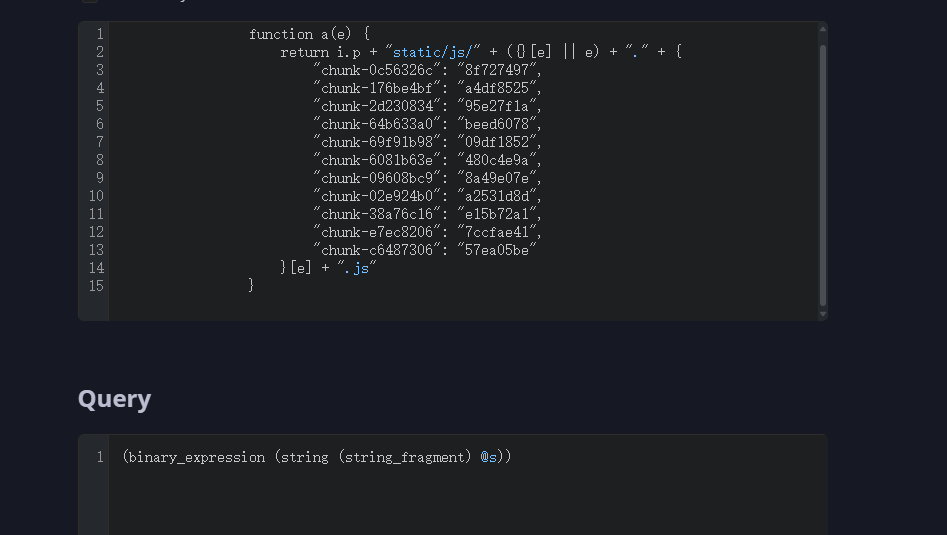
我在前端搜索这些js文件的文件名片段,找到了一段代码
俺寻思分段加载的js文件全都在这里,这些文件里面肯定有更多亟待发现的API端点
您猜怎么着?这就轮到我们tree-sitter出场啦,这款语义分析工具天生我材必有用,这下专业对口了
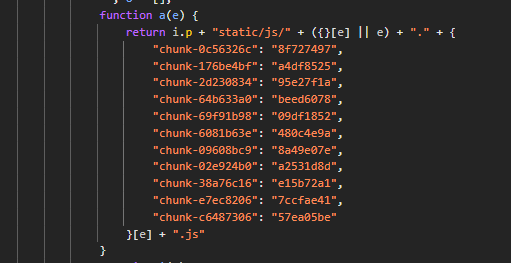
简化一下上面这段代码,放到tree-sitter的playground上面,解析出来的语法树差不多是这样:
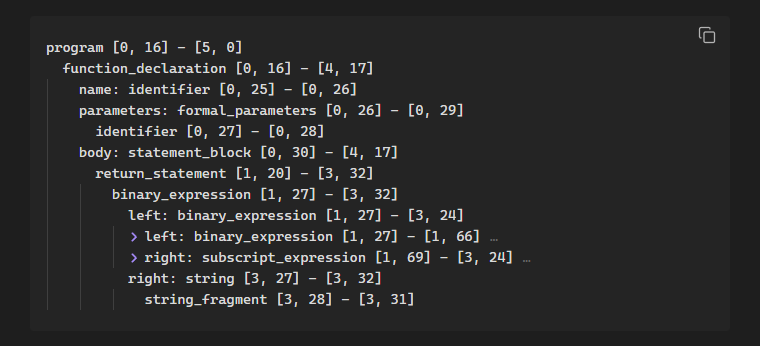
program [0, 16] - [5, 0]
function_declaration [0, 16] - [4, 17]
name: identifier [0, 25] - [0, 26]
parameters: formal_parameters [0, 26] - [0, 29]
identifier [0, 27] - [0, 28]
body: statement_block [0, 30] - [4, 17]
return_statement [1, 20] - [3, 32]
binary_expression [1, 27] - [3, 32]
left: binary_expression [1, 27] - [3, 24]
left: binary_expression [1, 27] - [1, 66]
left: binary_expression [1, 27] - [1, 60]
left: binary_expression [1, 27] - [1, 45]
left: member_expression [1, 27] - [1, 30]
object: identifier [1, 27] - [1, 28]
property: property_identifier [1, 29] - [1, 30]
right: string [1, 33] - [1, 45]
string_fragment [1, 34] - [1, 44]
right: parenthesized_expression [1, 48] - [1, 60]
binary_expression [1, 49] - [1, 59]
left: subscript_expression [1, 49] - [1, 54]
object: object [1, 49] - [1, 51]
index: identifier [1, 52] - [1, 53]
right: identifier [1, 58] - [1, 59]
right: string [1, 63] - [1, 66]
string_fragment [1, 64] - [1, 65]
right: subscript_expression [1, 69] - [3, 24]
object: object [1, 69] - [3, 21]
pair [2, 24] - [2, 52]
key: string [2, 24] - [2, 40]
string_fragment [2, 25] - [2, 39]
value: string [2, 42] - [2, 52]
string_fragment [2, 43] - [2, 51]
index: identifier [3, 22] - [3, 23]
right: string [3, 27] - [3, 32]
string_fragment [3, 28] - [3, 31]这段语法树用眼睛看肯定是会看麻的,不过我们只需要注意两个特征,第一个特征是那个一大堆chunk字符串的map结构,非常显眼,对应语法树的object节点;第二个特征是那段代码最后的“.js”字符串,这个字符串跟那个飞天大map做了字符串拼接操作,对应语法树里subscript_expression的上级节点和string做拼接操作
其实刚刚发现上面的语法树放到obsidian里面方便查看一点
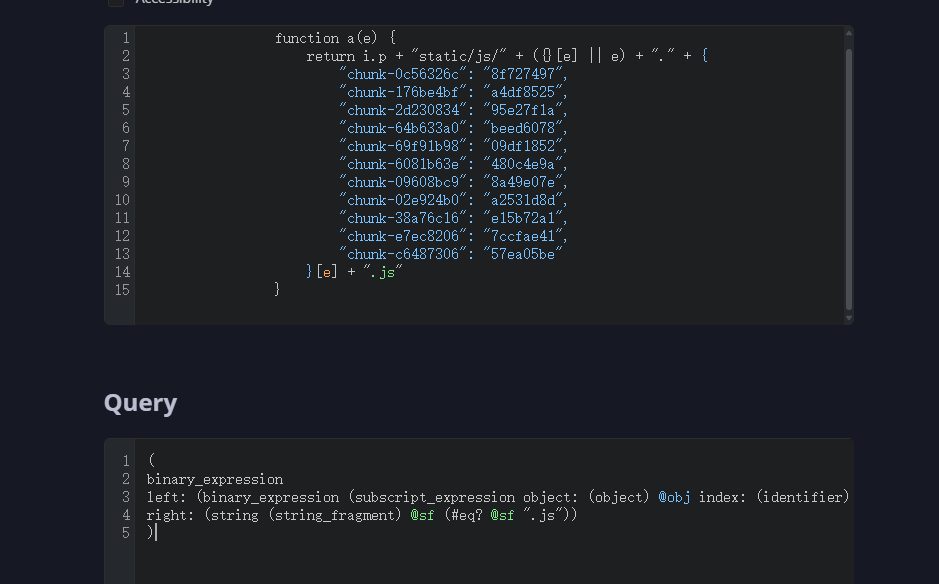
然后就可以根据这个语法树结构写代码查询了,匹配飞天大map的查询语句如下
(
binary_expression
left: (binary_expression (subscript_expression object: (object) @obj index: (identifier) @id))
right: (string (string_fragment) @sf (#eq? @sf ".js"))
)下图标蓝的部分就是匹配出来的飞天大map,再拿这段匹配出来的代码去做字符串提取,就能拼出来js文件的名字了
但是还没有结束,不是拼出js文件的名字就结束了,细心的大伙一定会注意到,这一段代码前面有一句“static/js/”,说明这些js文件存储在这个目录下的
这个“static/js/”不知道能不能被程序员修改,如果万一改了呢?所以我必须再匹配这个js路径前缀
考虑到刚才已经成功匹配飞天大map,我们是不是能在刚才的代码查询语句上略施手脚,从而匹配到路径前缀呢?
答案是困难的,因为你别看它俩离得近,实际上距离差了好几个运算符,这对应到语法树里那可是深了几级的关系,这意味着我的查询必须写得更大、更难看
那怎么办呢
不妨粗暴一点,直接把参与拼接的字符串全部干出来,基本上也误匹配的数量不会增加太多,问题不大
最后形成代码,输出js路径
from tree_sitter import Parser, Language
def webpack_caps(tree, lang: Language, paser: Parser):
query = lang.query('''
(
binary_expression
left: (binary_expression (subscript_expression object: (object) @obj index: (identifier) @id))
right: (string (string_fragment) @sf (#eq? @sf ".js"))
)
''')
caps = query.captures(tree.root_node)
if len(caps) == 0 or 'obj' not in caps:
return []
jfs = []
for cap in caps['obj']:
tre = paser.parse(cap.text)
qur = lang.query('(string_fragment) @pair_str')
cps = qur.captures(tre.root_node)
js_frag = ''
if len(cps) == 0:
return []
cps['pair_str'].sort(key=lambda x: x.start_byte)
for i in range(len(cps['pair_str'])):
pair = cps['pair_str'][i]
js_frag += pair.text.decode('utf-8') + '.'
if i % 2 != 0:
js_frag += 'js'
jfs.append(js_frag)
js_frag = ''
res = []
q_pfx = lang.query('''
(binary_expression (string (string_fragment) @s))
''')
caps = q_pfx.captures(tree.root_node)
if 's' not in caps:
return []
for i in caps['s']:
for j in jfs:
tmp = '/'+i.text.decode('utf8')+'/'+j
while '//' in tmp:
tmp = tmp.replace('//', '/')
res.append(tmp)
return res今天直接刻不容缓拿到渗透项目上使用,工具是没啥问题,就是加密和签名逆向起来感觉不太方便,又想写代码了
Comments | NOTHING