

最近总是感觉天天写代码非常没意思,因为虽然我NAS上的代码仓库数量高达47个,但是深受自己/大家喜爱的项目大约不超过10个,也就是说,我写一天代码8个小时,只有2个小时是有用的,当然大伙爱用的项目的维护成本也非常高,比如目前决定给扫描器平台添加那7-8个改进;或者是不是重构报告平台——用框架级的成熟稳定的协作机制实现报告编辑的“行级锁定”;又或者把大活进行到底(解决rust实现的内网穿透工具在延迟不高不低时丢包的问题)
维护一个项目真的很无聊,因为维护的时候已然没有对新事物的好奇,也没有学习过后如获至宝的“卧槽这个框架好用原理有意思真的很高效你看鲁棒性多强”,只是在耕耘阳台的两盆花,努力不让它们似去。真的很无聊,而且累
但是有时候学习新的技术也很无聊,因为学到新东西的感觉也是一成不变的,有时候会怀疑学这些东西真的有用吗,因为感觉学技术会让自己变得无趣,想要大伙和自己开心只能搞搞抽象,人生不如头脑发热灵光乍现开启新赛道开发新需求开启新征程来的耀眼(来钱快)
走技术路无疑是苦行,但是我也没有什么别的能力和机会,就只做做技术,所以我今天接着跟大伙聊技术
其实之前做过python语法转mongo查询的东西,也是基于语义分析技术,可是到最后也没用上,因为这个是资产测绘系统用的,做这种事情需要一支专业团队,个人做这个没有意义,钱也不是大风刮来的,就算大风刮来了钱,花掉了也要能赚回来,要想“风雨欲来”,也要有人做法,本法师经过可行性研究,决定不做
大伙可能都记得lex和yacc的痛苦,但是tree-sitter就很SuperIdol的笑容都没你的甜,因为它会把一段python长难句翻译成可爱的语法树(LovelyAST)。举个例子:
'blog' in title and ('<div>' in body or '<script>' not in body)
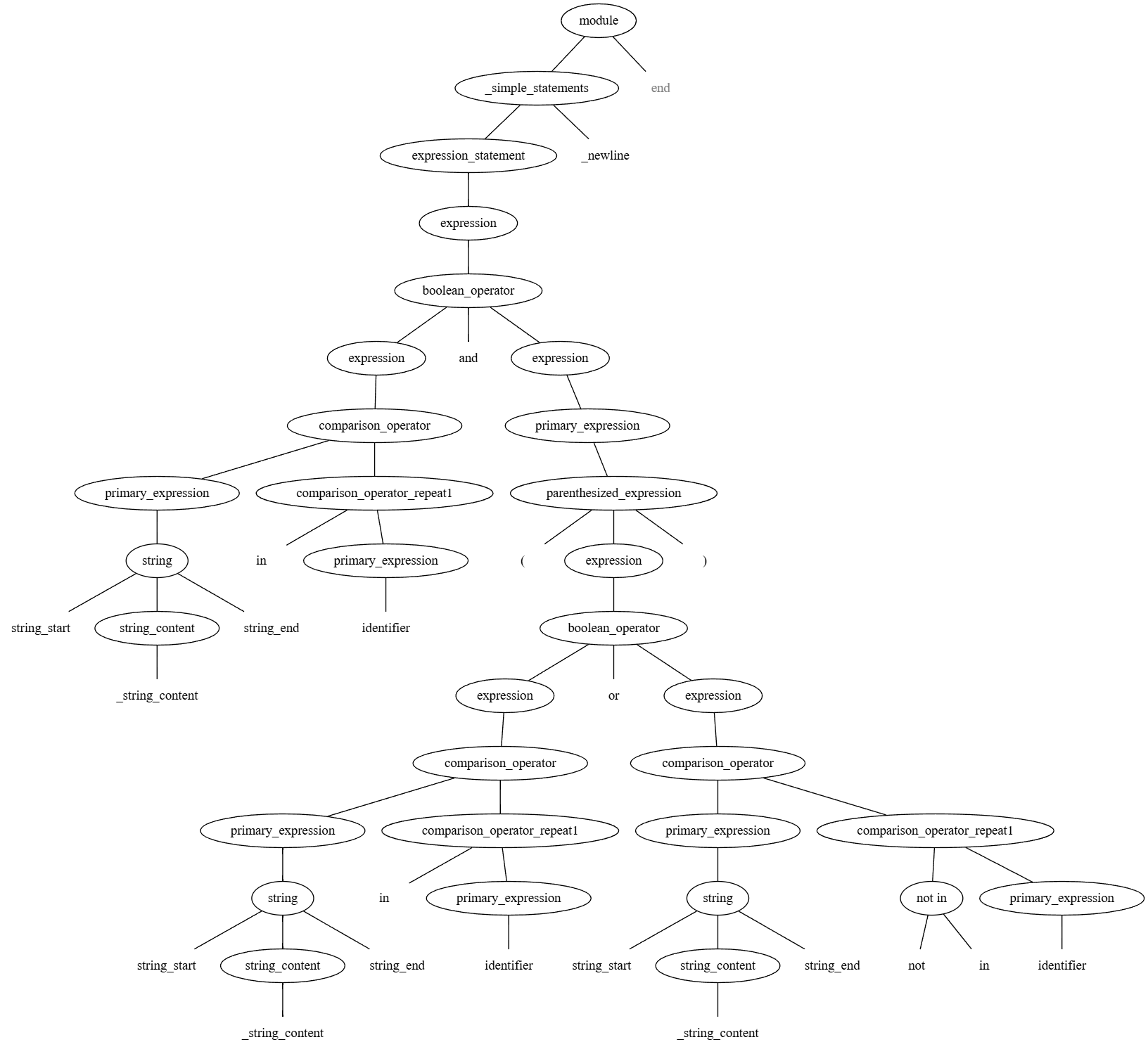
看到这里大伙应该明白我要做什么了,我打算做一个网络空间测绘引擎的聚合系统,热心的大伙贡献自己的VIP账号,却是担心自己的账号被人“谭中闲鱼百许元,我是学生白送我”,而且大伙的号五花八门,有Hunter的、quake、fofa的,大伙希望这些账号“用到正途”、都别闲着,使劲查、一起查、一个都逃不掉,所有积分全部用完。因此我感觉存在这个潜在的“聚合查询”需求,所以才开始做表达式代码转换
虽然上面那个胖胖的语法树不是那么小巧,但是能“一条路走到黑”,可以看到tree-sitter帮我们把句子分成了“奶龙尸块”,我们只需要写代码对每个块进行解析即可

因为表达式语法比较简单,所以我只需要做“boolean_opreator”和“comparsion_operator”的处理即可,其实说难也不难,说简单也很简单,主要难的是怎么把代码写的优雅;像我这种干渗透的,可以“富丽堂皇”的说我不会写代码,所以代码写的很丑,idea编辑器上全是绿绿的、黄黄的,只要没有红红的,能跑就行
哦,灰灰的也没有,我不写注释的
为了防止大家不看,我先画逻辑流程图再给代码
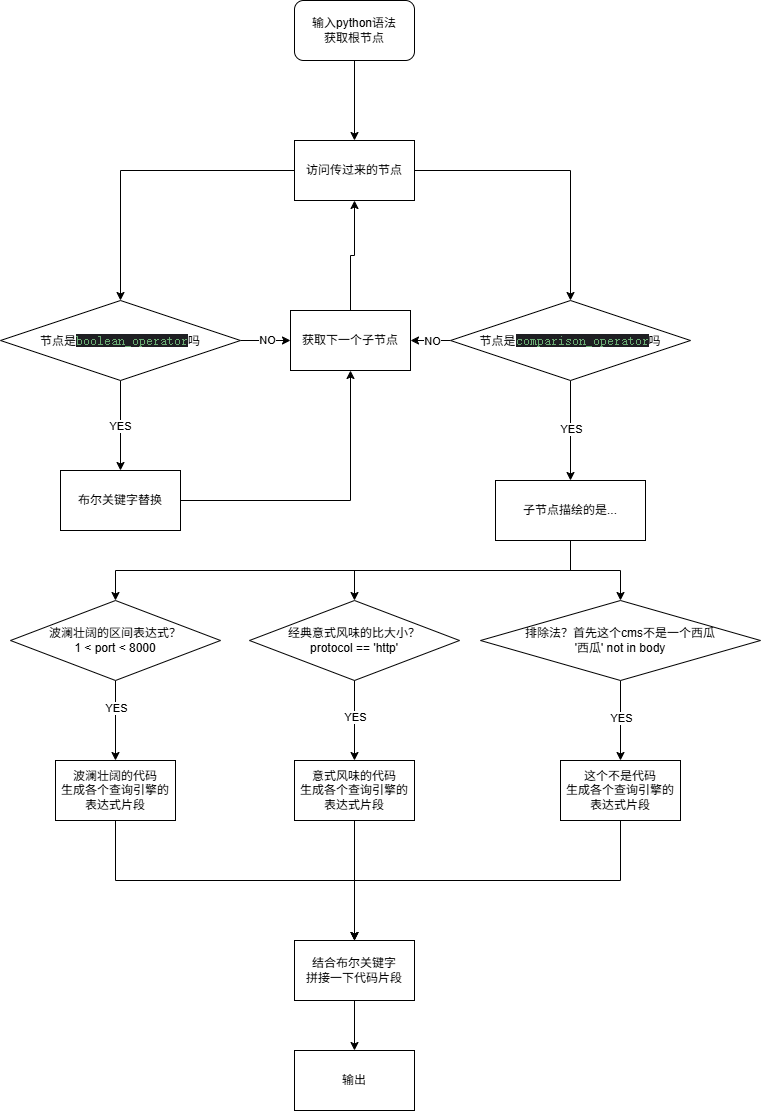
试用一下,感觉能用,应该会有bug,我目前能想象出来有bug,但是我坚定地相信大家,用不出来
用出来了就自适应一下,我就不修了
LanguageTranslator translator = new LanguageTranslator();
Map<String, String> res = translator.translate("'blog' in title and ('<div>' in body or '<script>' not in body)");
for (String key : res.keySet()) {
System.out.println(key + " : " + res.get(key));
}
虽然代码很丑,但是能跑,不要要求那么多
package online.zgbsm.tokencluster.tools;
import org.treesitter.*;
import java.util.*;
public class LanguageTranslator {
String expression;
Map<String, String> identFofa = new HashMap<>();
Map<String, String> identQuake = new HashMap<>();
Map<String, String> identHunter = new HashMap<>();
public LanguageTranslator() {
identFofa.put("province", "region");
identFofa.put("icp_number", "icp");
identHunter.put("port", "ip.port");
identHunter.put("country", "ip.country");
identHunter.put("city", "ip.city");
identHunter.put("province", "ip.province");
identHunter.put("os", "ip.os");
identHunter.put("app", "app.name");
identHunter.put("title", "web.title");
identHunter.put("body", "web.body");
identHunter.put("icp_number", "icp.number");
identHunter.put("icp_name", "icp.name");
identQuake.put("header", "headers");
identQuake.put("icp_number", "icp");
identQuake.put("icp_name", "icp_keywords");
}
public Map<String, String> translate(String python) {
expression = python;
TSParser tsParser = new TSParser();
TSLanguage py = new TreeSitterPython();
tsParser.setLanguage(py);
TSTree tree = tsParser.parseString(null, python);
if (tree.getRootNode().hasError()) {
return null;
}
return travel(tree.getRootNode());
}
Map<String, String> travel (TSNode node) {
// 如果当前子节点是 comparison_operator 或 boolean_operator,就call对应的方法去处理,对应的方法返回3个引擎的表达式片段,然后本方法组合返回最终结果
Map<String, String> res = new HashMap<>(Map.of("hunter", "", "quake", "", "fofa", ""));
switch (node.getType()) {
case "boolean_operator":
Map<String, String> bres = bool_engine(node);
res.replaceAll((k, v) -> res.get(k) + bres.get(k));
break;
case "comparison_operator":
Map<String, String> cres = comparison_engine(node);
res.replaceAll((k, v) -> res.get(k) + cres.get(k));
break;
case "integer":
break;
case "string_content":
break;
case "identifier":
break;
default:
if (node.isNamed()) {
for (int i = 0; i < node.getChildCount(); i++) {
TSNode child = node.getChild(i);
Map<String, String> tr = travel(child);
for (String key : tr.keySet()) {
res.put(key, res.get(key) + tr.get(key));
}
}
} else {
String typ = node.getType();
res.replaceAll((k, v) -> res.get(k) + typ);
}
break;
}
return res;
}
Map<String, String> bool_engine(TSNode node) {
Map<String, String> res = new HashMap<>(Map.of("hunter", "", "quake", "", "fofa", ""));
Map<String, String> dict = Map.of("and", "&&", "or", "||");
for (int i = 0; i < node.getChildCount(); i++) {
if (node.getChild(i).isNamed()) {
Map<String, String> tmp = travel(node.getChild(i));
res.replaceAll((k, v) -> res.get(k) + tmp.get(k));
} else {
String op = node.getChild(i).getType();
res.replaceAll((k, v) -> {
switch (k) {
case "hunter":
case "fofa":
return v + " " + dict.get(op) + " ";
case "quake":
return v + " " + op.toUpperCase() + " ";
}
return v + " " + op + " ";
});
}
}
return res;
}
Map<String, String> comparison_engine(TSNode node) {
Map<String, String> res = new HashMap<>(Map.of("hunter", "", "quake", "", "fofa", ""));
if (node.getChildCount() == 5) {
// 区间查询语法
Set<String> lower = new HashSet<>(Set.of("<", "<="));
String l;
String r;
String ident;
int lStart = node.getChild(0).getStartByte();
int lEnd = node.getChild(0).getEndByte();
l = expression.substring(lStart, lEnd);
int rStart = node.getChild(4).getStartByte();
int rEnd = node.getChild(4).getStartByte();
r = expression.substring(rStart, rEnd);
int identStart = node.getChild(2).getStartByte();
int identEnd = node.getChild(2).getEndByte();
ident = expression.substring(identStart, identEnd);
String op1 = node.getChild(1).getType();
String op2 = node.getChild(3).getType();
if (lower.contains(node.getChild(1).getType()) && lower.contains(node.getChild(3).getType())) {
res.replaceAll((k, v) -> {
switch (k) {
case "fofa":
break;
case "quake":
return identQuake.getOrDefault(ident, ident) + ":[ " + l + " TO " + r +" ]";
case "hunter":
return identHunter.getOrDefault(ident, ident) + op1 + "\"" + l + "\"" + " && " + identHunter.getOrDefault(ident, ident) + op2 + "\"" + r + "\"";
}
return "";
});
} else {
res.replaceAll((k, v) -> {
switch (k) {
case "fofa":
break;
case "quake":
return identQuake.getOrDefault(ident, ident) + ":[ " + r + " TO " + l +" ]";
case "hunter":
return identHunter.getOrDefault(ident, ident) + op1 + "\"" + l + "\"" + " && " + identHunter.getOrDefault(ident, ident) + op2 + "\"" + r + "\"";
}
return "";
});
}
} else if (node.getChildCount() == 3) {
// 正常语法,大于小于、in、not in
String op = node.getChild(1).getType();
String l = node.getChild(0).getType();
String r = node.getChild(2).getType();
if (l.equals("identifier")) {
String fl = expression.substring(node.getChild(0).getStartByte(), node.getChild(0).getEndByte());
TSNode rn = node.getChild(2);
if (r.equals("string")) {
rn = node.getChild(2).getChild(1);
}
String finalR = expression.substring(rn.getStartByte(), rn.getEndByte());
switch (op) {
case "<":
case "<=":
res.replaceAll((k, v) -> {
switch (k) {
case "fofa":
break;
case "quake":
return identQuake.getOrDefault(fl, fl) + ":[ * TO " + finalR +" ]";
case "hunter":
return identHunter.getOrDefault(fl, fl) + op + "\"" + finalR + "\"";
}
return "";
});
break;
case ">":
case ">=":
res.replaceAll((k, v) -> {
switch (k) {
case "fofa":
break;
case "quake":
return identQuake.getOrDefault(fl, fl) + ":[ " + finalR + " TO * ]";
case "hunter":
return identHunter.getOrDefault(fl, fl) + op + "\"" + finalR + "\"";
}
return "";
});
break;
case "==":
res.replaceAll((k, v) -> switch (k) {
case "fofa" -> identFofa.getOrDefault(fl, fl) + "==\"" + finalR + "\"";
case "quake" -> identQuake.getOrDefault(fl, fl) + ":\"" + finalR + "\"";
case "hunter" -> identHunter.getOrDefault(fl, fl) + "==\"" + finalR + "\"";
default -> "";
});
break;
case "in":
res.replaceAll((k, v) -> switch (k) {
case "fofa" -> identFofa.getOrDefault(fl, fl) + "=\"" + finalR + "\"";
case "quake" -> identQuake.getOrDefault(fl, fl) + ":\"" + finalR + "\"";
case "hunter" -> identHunter.getOrDefault(fl, fl) + "=\"" + finalR + "\"";
default -> "";
});
break;
case "!=":
case "not in":
res.replaceAll((k, v) -> switch (k) {
case "fofa" -> identFofa.getOrDefault(fl, fl) + "!=\"" + finalR + "\"";
case "quake" -> "NOT " + identQuake.getOrDefault(fl, fl) + ":\"" + finalR + "\"";
case "hunter" -> identHunter.getOrDefault(fl, fl) + "!=\"" + finalR + "\"";
default -> "";
});
break;
}
} else {
String fr = expression.substring(node.getChild(2).getStartByte(), node.getChild(2).getEndByte());
TSNode ln = node.getChild(0);
if (l.equals("string")) {
ln = node.getChild(0).getChild(1);
}
String finalL = expression.substring(ln.getStartByte(), ln.getEndByte());
switch (op) {
case "<":
case "<=":
res.replaceAll((k, v) -> {
switch (k) {
case "fofa":
break;
case "quake":
return identQuake.getOrDefault(fr, fr) + ":[ " + finalL + " TO * ]";
case "hunter":
return identHunter.getOrDefault(fr, fr) + (op.equals("<") ? ">" : ">=") + finalL;
}
return "";
});
break;
case ">":
case ">=":
res.replaceAll((k, v) -> {
switch (k) {
case "fofa":
break;
case "quake":
return identQuake.getOrDefault(fr, fr) + ":[ * TO " + finalL + " ]";
case "hunter":
return identHunter.getOrDefault(fr, fr) + (op.equals(">") ? "<" : "<=") + "\"" + finalL + "\"";
}
return "";
});
break;
case "==":
res.replaceAll((k, v) -> switch (k) {
case "fofa" -> identFofa.getOrDefault(fr, fr) + "==\"" + finalL + "\"";
case "quake" -> identQuake.getOrDefault(fr, fr) + ":\"" + finalL + "\"";
case "hunter" -> identHunter.getOrDefault(fr, fr) + "==\"" + finalL + "\"";
default -> "";
});
break;
case "in":
res.replaceAll((k, v) -> switch (k) {
case "fofa" -> identFofa.getOrDefault(fr, fr) + "=\"" + finalL + "\"";
case "quake" -> identQuake.getOrDefault(fr, fr) + ":\"" + finalL + "\"";
case "hunter" -> identHunter.getOrDefault(fr, fr) + "=\"" + finalL + "\"";
default -> "";
});
break;
case "!=":
case "not in":
res.replaceAll((k, v) -> switch (k) {
case "fofa" -> identFofa.getOrDefault(fr, fr) + "!=\"" + finalL + "\"";
case "quake" -> "NOT " + identQuake.getOrDefault(fr, fr) + ":\"" + finalL + "\"";
case "hunter" -> identHunter.getOrDefault(fr, fr) + "!=\"" + finalL + "\"";
default -> "";
});
break;
}
}
}
return res;
}
}
Comments | NOTHING